


Executive Summary
- Through analysis of robots.txt files, Censys identified over 60 cryptocurrency phishing pages impersonating popular hardware wallet brands Trezor and Ledger. Notably, the actor behind the pages attempted to block popular phishing reporting sites from indexing the pages by including endpoints of the phish reporting sites in their own robots.txt file.
- At the time of analysis, all but 3 were hosted on Cloudflare’s free hosting solution, Pages. Cloudflare has since taken nearly all of the sites down or marked them as suspected phishing. The 3 sites hosted on custom domains are no longer live as of this publication. We also identified the use of multiple other free web hosting providers for similar spoofed cryptocurrency-themed pages.
- Using the unusual robots.txt file, we identified multiple GitHub repositories with code for crypto phishing pages that contain merge conflicts in the README file, further suggesting the actor behind these sites may not be the most well-versed in web development.
Introduction
Good cryptocurrency phishing campaigns are a satoshi a dozen, but sometimes the not-so-good campaigns are even more intriguing. We recently identified a cryptocurrency wallet phishing campaign with some interesting characteristics. The sites impersonated those of the popular hardware cryptocurrency wallets Ledger and Trezor, two common targets of phishing activity. So common, in fact, that these wallet manufacturers have dedicated pages on their websites detailing scams targeting their customers, along with guidance on how to identify them.
There are two major categories of cryptocurrency wallets, each with different variants: online, or hot wallets, and offline, or cold wallets. Online wallets offer a convenient, easily accessible way to manage cryptocurrency funds, but they’re inherently less secure than offline wallets due to their Internet connectivity. Hardware wallets are a type of offline wallet, and are often adopted by more security-conscious cryptocurrency users. In addition to being a physical device similar in size to a USB drive, they are not connected to the Internet by default.
Identifying the Phish Pages
While exploring data in Censys Platform, we identified over 60 spoofed crypto hardware wallet sites with an interesting entry in their robots.txt file: “Disallow: /add_web_phish.php.” Below are some examples of pages we identified, along with the real brand’s site for comparison.
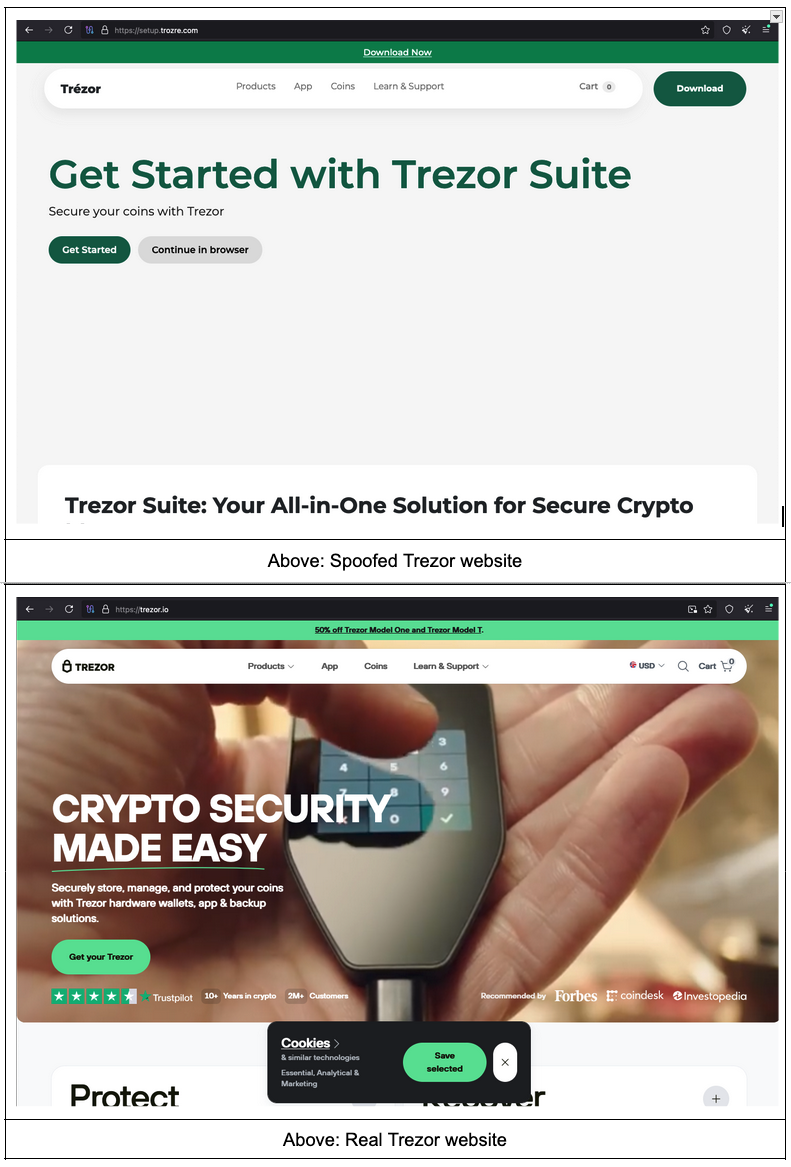
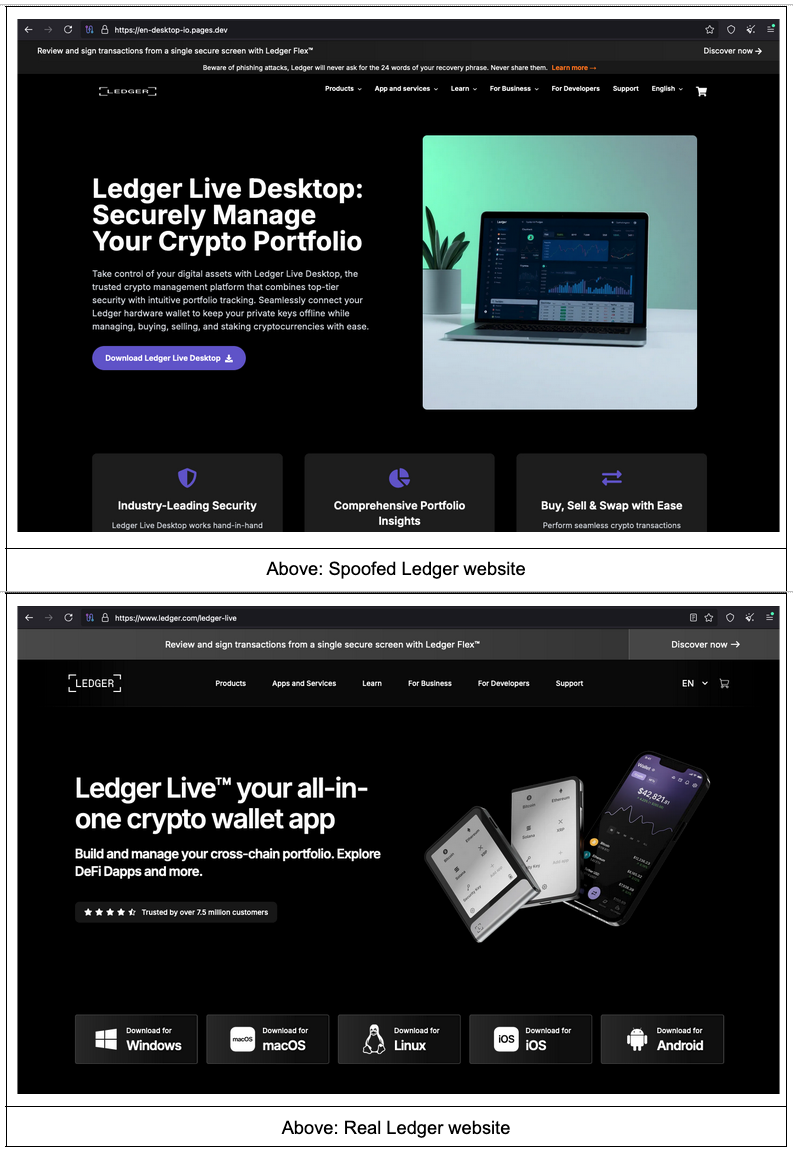
The spoofed sites are similar to, though not exact clones of, the original sites, and some appear to be missing key imagery (e.g., the notable whitespace in the spoofed Trezor site shown above). While the real and faux sites clearly differ when observed together, the spoofed sites might be convincing to a user acting on a message purporting to be about account security or safety of their funds. Notably, the spoofed Ledger site shown above includes a banner warning about phishing attacks in an attempt to appear more legitimate.
A Closer Look at robots.txt
The robots.txt file found on these pages is what originally helped identify them, and it’s worth examining in greater detail. Below is the specific robots.txt file found on all of the sites, with the “Sitemap” section adapted to reflect the URL of each site:
User-agent: * Disallow: /admin/ Disallow: /scripts/ Disallow: /private/ Disallow: /tmp/
Disallow: /add_web_phish.php Disallow: /en-us/report Disallow: /report Disallow: /phish.report
Allow: / # Sitemap Sitemap: https://setup.trozre[.]com/sitemap.xmlNow is probably a good time to talk about what a robots.txt file does–and does not–do. Robots.txt is the implementation of The Robots Exclusion Protocol, a 30-year-old standard designed to provide web crawlers and bots with instructions about how to appropriately access a given website. This is accomplished by explicitly outlining which endpoints on a website bots and scanners are allowed (and not allowed) to crawl. The robots.txt file should be placed in the top level directory of a site, such as example[.]com/robots.txt, where crawlers and bots will know to look for it.
While most major bots and crawlers respect the contents of robots.txt, there is no enforcement beyond reliance on voluntary compliance. Robots.txt files are public and can be scanned by any service with access to the Internet (including Censys), so they should never contain information about truly sensitive endpoints. Robots.txt also doesn’t prevent specific referers from accessing any parts of a website.
To explore this in practice, we can analyze the robots.txt file found on these phishing pages (formatted for clarity):
User-agent: *
Disallow: /admin/
Disallow: /scripts/
Disallow: /private/
Disallow: /tmp/
Disallow: /add_web_phish.php
Disallow: /en-us/report
Disallow: /report
Disallow: /phish.report
Allow: /
# Sitemap Sitemap: https://setup.trozre[.]com/sitemap.xm| Parameter | Explanation |
| User-agent | The contents of this robots.txt file apply to any bot, as the value is a wildcard (*). |
| Disallow | Bots should not crawl any endpoints on the site prefaced with “Disallow.” |
| Allow | Bots are allowed to crawl any endpoint prefaced with “Allow.” In this case (“/”), bots are allowed to crawl any endpoint on the website apart from those explicitly disallowed above. |
| Sitemap | The sitemap tells bots and crawlers what endpoints exist on the site so they can scan each allowed endpoint more efficiently. |
In these robots.txt files, we see multiple common endpoints listed as “Disallow:”:
- /admin
- /scripts
- /private
- /tmp
However, the next few “Disallow” entries are a bit less straightforward:
- /add_web_phish.php
- /en-us/report
- /report
- /phish.report
In particular, “/add_web_phish.php” looked vaguely familiar, and a quick web search indicated that this is the URL for submitting a phish page to PhishTank. A bit more searching revealed that each of these endpoints appear to be references to phish reporting sites:
- /add_web_phish.php – PhishTank
- /en-us/report – ESET
- /report – Netcraft
- /phish.report – Phish Report
Given what we know about robots.txt, this seems nonsensical. We hypothesize that in a misguided attempt to block various phishing reporting sites from indexing or scanning their spoofed pages, the actor added endpoints from the reporting sites themselves to their own robots.txt file.
Said differently, the actor behind these sites apparently completely misunderstood the function and intent of robots.txt, a decades-old standard that has absolutely nothing to do with blocking referral sources of web traffic.
Casting a net on GitHub
We were curious if this unusual robots.txt pattern could be found elsewhere and identified several examples on GitHub.
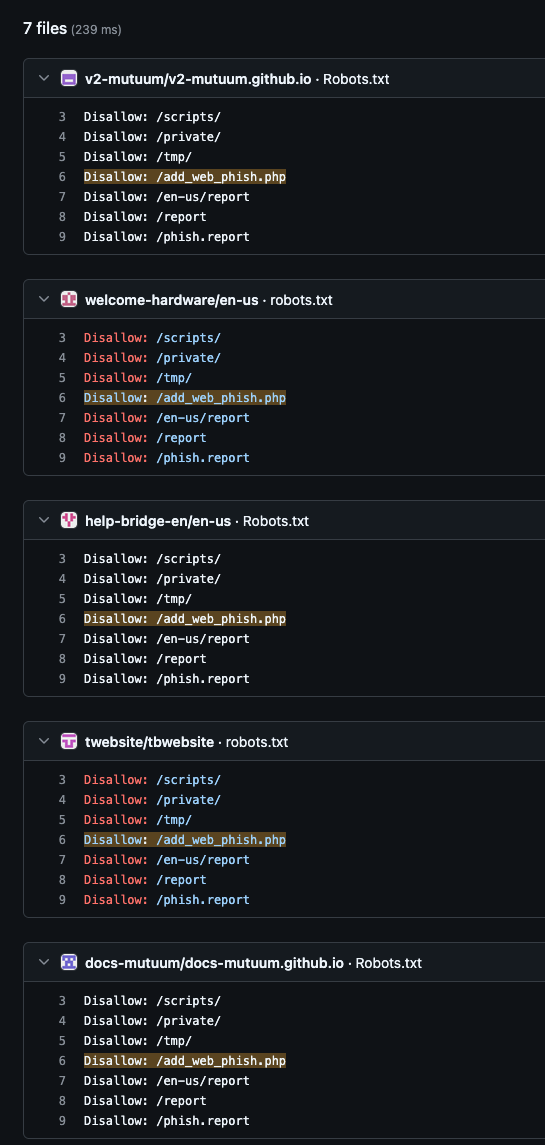
Each repository that contains this robots.txt file shares a common theme of cryptocurrency or decentralized finance (DeFi) spoof pages. They also have a similar structure and most include, among other files, the robots.txt file, index.html for the spoofed page, sitemap.xml, and a README that, in every case but one, reads simply, “en-us.”
In these repos, the earliest commit we can find dates back to January 22, 2025 in “welcome-hardware.” The index.html page added in the initial commit contains the HTML title “Trézor® Hardware® – Wallet | Starting Up Your Device | Trézor®,” suggesting these pages were at least planned several months prior to when our team first observed them. This is also similar to the format and style of the HTML titles we observed on the spoofed pages.
Further scrutinizing these repositories, we note that the README file in the “tbwebsite” repo appears to reflect unresolved Git merge conflicts.
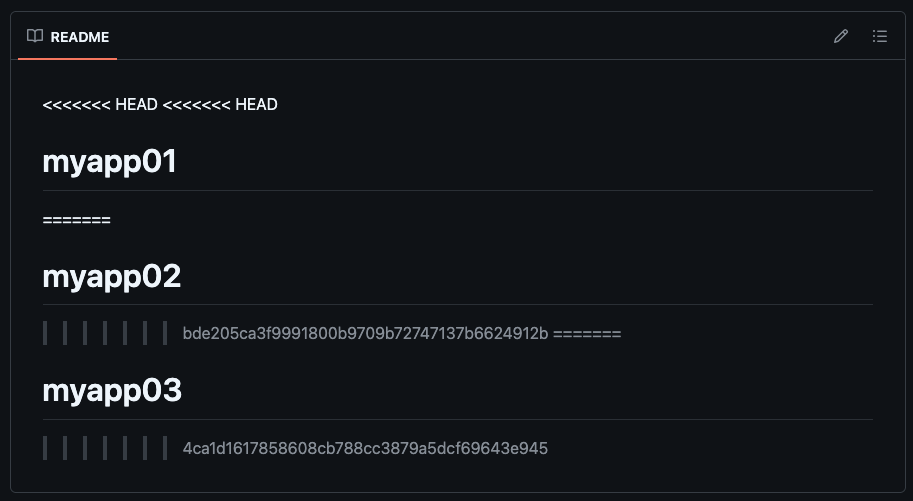
We identified 4 additional repositories with identical README files, including the same commit hashes for “myapp02” and “myapp03,” which could point to an attempt at automated development or repos created from the same corrupted template. They’re slightly different from the repos explored above in that they all contain a “.readthedocs.yaml” file and do not contain an index.html file that spoofs a common cryptocurrency brand. However, the presence of READMEs identical to that found in “tbwebsite,” which also contains the unusual robots.txt file, could suggest the same actor is responsible for each set of repositories.
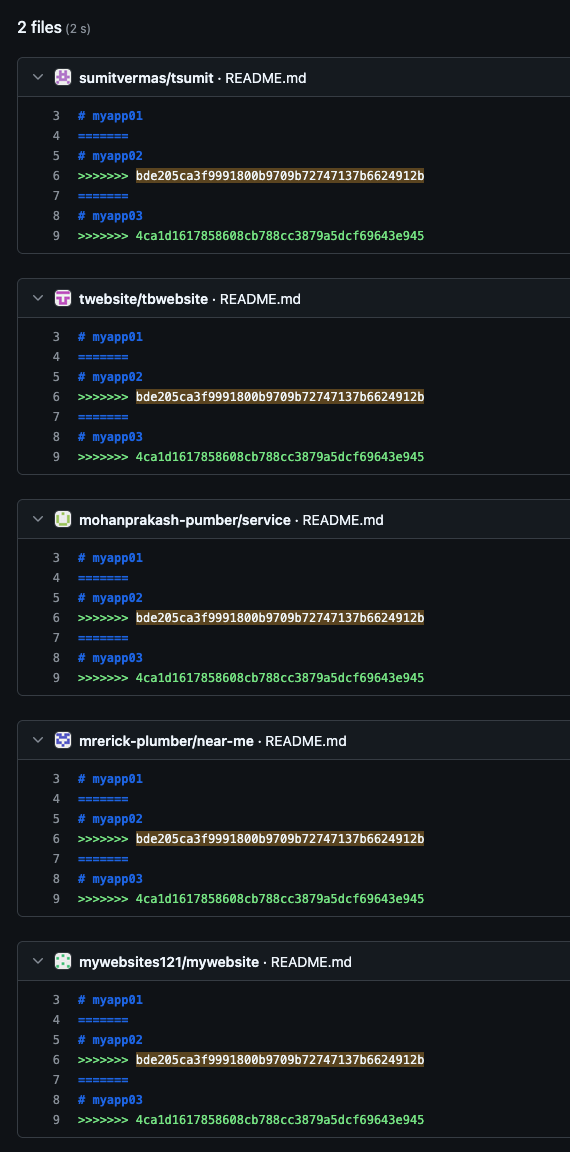
The misuse of robots.txt and the merge conflicts found in multiple READMEs could also suggest that the actor behind these pages is not well-versed in web development practices.
Profiling the web properties
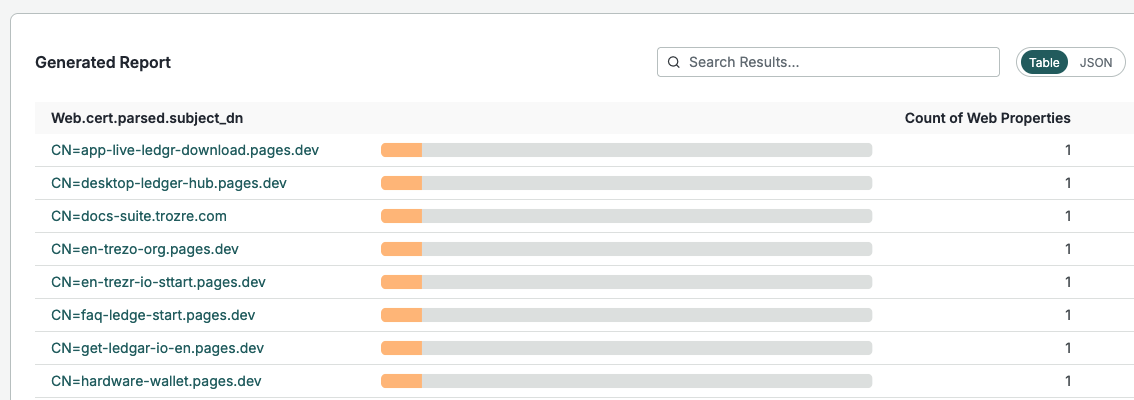
Upon initial discovery of this campaign, we identified 61 different hostnames*, all but 3 of which were hosted on Cloudflare Pages. The sites use some combination of misspelled versions of “Ledger” or “Trezor,” along with strings like “app,” “start,” “guide,” and “help.” All sites have TLS certificates, and the subject DNs match the hostnames of the sites.
*This link shows any sites that are currently live, but the full list of hostnames can be found in a Gist at the end of this post.
Static page hosting
While the sites we identified were primarily hosted on Cloudflare Pages, it isn’t the only service being leveraged to serve such content. A web search for some of the common hostname strings reveals a number of other providers, such as Netlify, Teachable, Bravenet Sites, and Typedream hosting similar pages. As of this analysis, many have been taken down and reported as malicious, but are still indexed on Google’s initial results page.
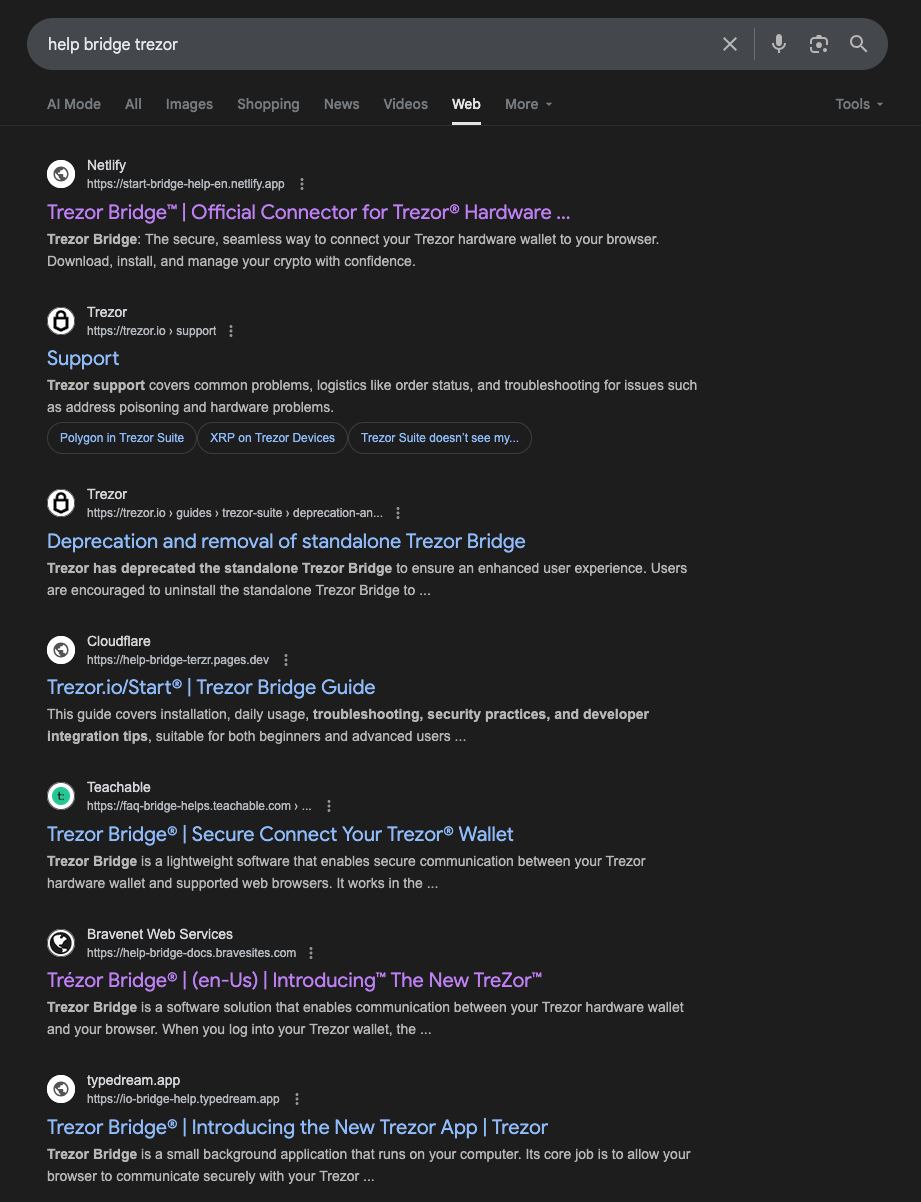
Static site generators and web hosting providers–especially those with free tiers–can be attractive targets for threat actors hoping to stand up pages spoofing popular brands. Smaller services in particular are less likely to have robust trust and safety or anti-abuse measures, allowing brand impersonation sites to avoid detection and remain online for longer periods of time than they might at larger providers.
Custom domains
Beyond sites found on Cloudflare Pages, two domains were observed among the sites with the unusual robots.txt file, “trozre[.]com” and “trzor[.]us.” Both domains were registered via GoDaddy, “trozre[.]com” on March 31 2025 and “trzor[.]us” on April 16 2025. The “trozre[.]com” registrant used WHOIS privacy, providing no meaningful pivots.
The “.us” TLD has been a popular choice for phishing websites in the past, but unlike “.com” and other common TLDs, this TLD does not permit WHOIS privacy:
Domain Name: trzor.us
Registry Domain ID: D5C02AB12BEC04BA78EFD63406A2BC40C-GDREG
Registrar WHOIS Server: whois.godaddy.com
Registrar URL: whois.godaddy.com
Updated Date: 2025-04-21T13:15:28Z
Creation Date: 2025-04-16T13:15:28Z
...
Registrant Name: miya bhai
Registrant Organization:
Registrant Street: Idukki
Registrant Street: Munnar
Registrant Street:
Registrant City: Munnar
Registrant State/Province: Andaman and Nicobar Islands
Registrant Postal Code: 685612
Registrant Country: in
Registrant Phone: +91.8750026216
Registrant Phone Ext:
Registrant Fax:
Registrant Fax Ext:
Registrant Email: xtreq185@gmail.com
Registrant Application Purpose: P3
Registrant Nexus Category: C11Unfortunately, the registrant information included in the WHOIS for “trzor[.]us” did not prove particularly useful for identifying related infrastructure or assets. From the WHOIS data, we were only able to identify a bare GitHub profile created on March 12, 2025 with the username “Xtreq185,” seen in the Registrant Email prefix. As of this publication, this domain has been repossessed by GoDaddy.
Examining web properties for each domain reveals multiple additional subdomains that do not appear to contain the robots.txt file:

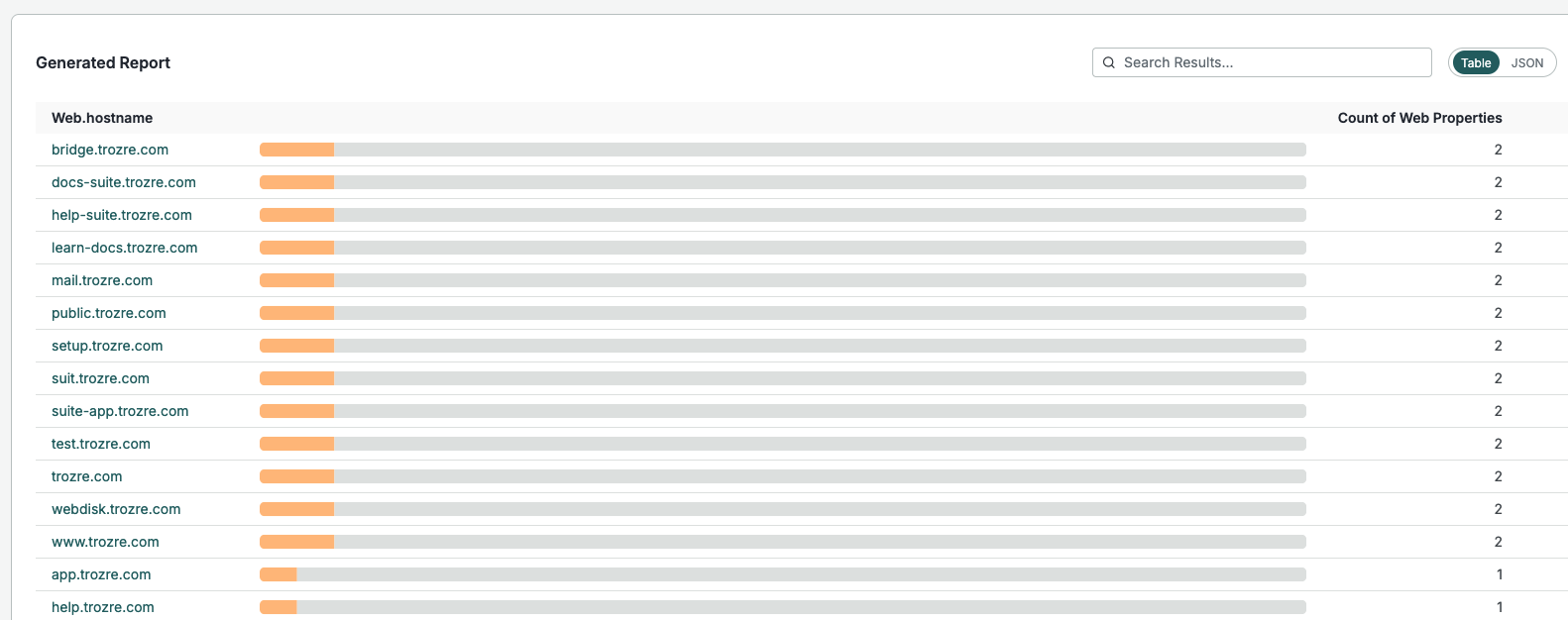
Conclusions
Cryptocurrency and adjacent technology remain popular targets for scams and phishing campaigns, despite attempts by cryptocurrency wallet manufacturers and cryptocurrency exchanges to raise user awareness about the issue. As with other types of fraud and phishing, the return on investment of time and capital can be enticing, requiring only a few victim clicks to make the campaign worthwhile for a threat actor.
This particular campaign suggests a lack of understanding of basic web technologies and standards, as evidenced by the misuse of robots.txt and multiple merge conflicts found in READMEs of associated GitHub repositories. Even so, while we don’t know whether links to these pages were actually sent to potential victims, it’s possible that an unsuspecting cryptocurrency wallet owner could be duped by the pages.
Finally, Censys’s scanning of robots.txt files enabled us to identify these sites. Beyond ports, services, and hosts on the Internet, the additional context of various endpoints enables deeper investigation and surfaces data that would otherwise remain lost in the noise.
Hostnames and HTML titles at time of initial analysis can be found in this GitHub gist.
Threats often hide in plain sight. Get visibility with Censys.


